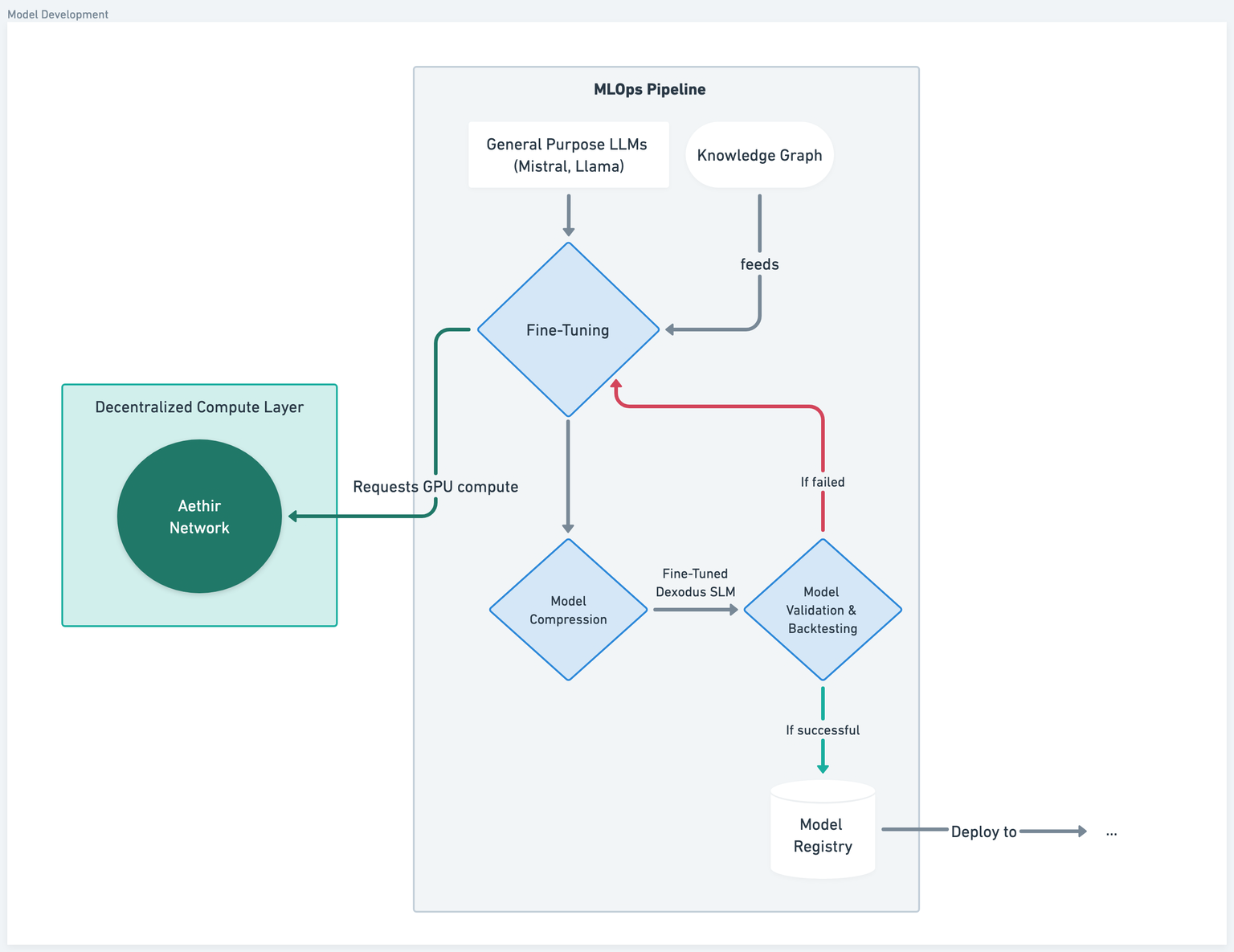
The Model Foundry
Our models are the product of a sophisticated MLOps pipeline designed for continuous improvement and specialization.
-
Foundation Models: We start with powerful, general-purpose Large Language Models (LLMs) that we select and test for the best possible outcome.
-
Knowledge Injection: These base models are then fed our proprietary DeFi Knowledge Graph. This is the secret sauce, containing a vast, structured repository of on-chain data, protocol mechanics, economic principles, and security audits.
-
Fine-Tuning: The fine-tuning process, where the model truly learns to specialize in DeFi, is computationally intensive. We request GPU compute from a decentralized compute layer, to power this stage efficiently and robustly.
-
Model Compression: After fine-tuning, the large model is distilled into a highly efficient Small Language Model (SLM). This step is critical for achieving the low latency and cost-efficiency our users require.
-
Validation & Backtesting: Before release, every Fine-Tuned Dexodus SLM undergoes rigorous validation and backtesting against historical and simulated DeFi scenarios. Models that do not meet our stringent performance and accuracy criteria are sent back for re-tuning.
-
Deployment: Successful models are pushed to our Model Registry and deployed as highly available API endpoints, ready for your agents to call.